Getting Started with Spring Cloud Data Flow on PCF Dev
In this article, I'd like to introduce how to use Spring Cloud Data Flow for Cloud Foundry on PCF Dev so that you can enjoy SCDF on your laptop.
We'll use 1.0.1.RELEASE version.
I won't describe "What is Spring Cloud Data Flow" here. I would recommend see Mark Pollack's Data Microservices in the Cloud at SpringOne Platform 2016. You can also watch the video.
TOC
Start PCF Dev
First of all, we need to downloa PCF Dev from Pivotal Network and install it. It's pretty easy. Please refer the following doc.
After installing, let's start PCF Dev.
cf dev start
After deploying a few streams, you'll find resources are not enough. I would recommend to use 8GB memory for PCFDev.
cf dev start -m 8192
After around 10~15 minutes, PCF Dev will be ready and you can login with:
cf login -a https://api.local.pcfdev.io --skip-ssl-validation -u admin -p admin -o pcfdev-org
Deploy Spring Cloud Data Flow Server
Next, we'll deploy Spring Cloud Data Flow Server to PCF Dev, which is responsible for deploying and managing streams and tasks.
Spring Cloud Dataflow uses:
- RabbitMQ (or Kafka) as a message broker between streaming apps
- MySQL to persist some states such as stream definitions, task execution histories.
- Redis for analytic services
All three backend services are ready in PCF Dev and you can provision as follows:
cf create-service p-mysql 512mb df-mysql
cf create-service p-rabbitmq standard df-rebbitmq
cf create-service p-redis shared-vm df-redis
Spring Cloud Data Flow Server and Shell for CLI can be downloaded as a standalone executable Spring Boot App.
wget http://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-server-cloudfoundry/1.0.1.RELEASE/spring-cloud-dataflow-server-cloudfoundry-1.0.1.RELEASE.jar
wget http://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-shell/1.0.1.RELEASE/spring-cloud-dataflow-shell-1.0.1.RELEASE.jar
Create manifest.yml to deploy the server and bind services to it.
---
applications:
- name: dataflow-server
memory: 1g
disk_quota: 2g
path: spring-cloud-dataflow-server-cloudfoundry-1.0.1.RELEASE.jar
buildpack: java_buildpack
services:
- df-mysql
- df-redis
env:
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_URL: https://api.local.pcfdev.io
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_ORG: pcfdev-org
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SPACE: pcfdev-space
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_DOMAIN: local.pcfdev.io
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_SERVICES: df-rebbitmq
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_USERNAME: admin
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_PASSWORD: admin
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SKIP_SSL_VALIDATION: true
MAVEN_REMOTE_REPOSITORIES_REPO1_URL: https://repo.spring.io/libs-snapshot
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_MEMORY: 512
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_DISK: 512
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_INSTANCES: 1
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_BUILDPACK: java_buildpack
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_ENABLE_RANDOM_APP_NAME_PREFIX: false
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_SERVICES: df-mysql
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_MEMORY: 512
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_DISK: 512
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_INSTANCES: 1
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_BUILDPACK: java_buildpack
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_ENABLE_RANDOM_APP_NAME_PREFIX: false
SPRING_CLOUD_DATAFLOW_FEATURES_EXPERIMENTAL_TASKSENABLED: true
Finally, you can deploy with:
cf push
You can go to Dashboard 😉
http://dataflow-server.local.pcfdev.io/dashboard
Deploy First Stream
Run SCDF shell to manage streams by CLI:
java -jar spring-cloud-dataflow-shell-1.0.1.RELEASE.jar
- Access to the server
- Import apps (modules used in streams)
- Deploy a stream
# **in your SCDF shell**
dataflow config server http://dataflow-server.local.pcfdev.io
app import --uri http://bit.ly/1-0-4-GA-stream-applications-rabbit-maven
stream create --name httptest --definition "http | log" --deploy
Your stream will be deployed. It might take a few minutes, so wait until stream list returns deployed. Don't care about first failed status.

App uri you import is listed on http://cloud.spring.io/spring-cloud-stream-app-starters/
Your first stream is super trivial.
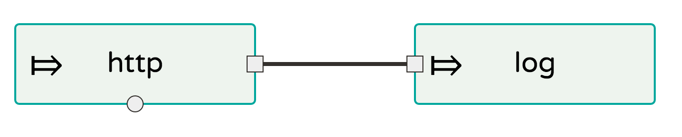
The source receives HTTP messages and send their request body to the next module, log sink in this case.
The sink just output the given payload to stdout.
You can consume message from log sink using cf logs :
# **in your terminal**
cf logs dataflow-httptest-log
Send a request to http source:
# **in your SCDF shell**
http post --target http://dataflow-httptest-http.local.pcfdev.io --data "hello world"
SCDF will look like:

And you can see sink log as follows:

To delete a stream, use stream destroy:
# **in your SCDF shell**
stream destroy --name httptest
You can also create streams using Dashboard GUI. Go to "STREAMS" tab and select "Create Stream". Write stream DSL like:
http | log
in the textarea. Your stream will be drawn under the textarea.

Click "Create Stream" button and the input stream name and check "Deploy stream(s)". Then click "Create" button.

You can see the status in the "Definitions" tab:

You can also see what applications are actually deployed (which are equivalent to cf apps) in the "Runtime" page:

You could destroy httptest stream to make sure running next example without an insufficient resource error.
Your first step has been finished! 🎉
Analyze Twitter Stream
Next, we will integrate Twitter stream to SCDF. This tutorial is based on spring-cloud-dataflow-samples.
We'll create three streams using twitterstream source.
Copy and paste the following three lines on the textarea. Note that you have to use your own consumerKey, consumerSecret, accessToken, accessTokenSecret retrieved from Twitter Developers site.
In spring-cloud-dataflow-shell, create and deploy the following streams
stream create tweets --definition "twitterstream --consumerKey=<CONSUMER_KEY> --consumerSecret=<CONSUMER_SECRET> --accessToken=<ACCESS_TOKEN> --accessTokenSecret=<ACCESS_TOKEN_SECRET> | log"
stream create --name tweetlang --definition ":tweets.twitterstream > field-value-counter --fieldName=lang --name=language"
stream create --name tagcount --definition ":tweets.twitterstream > field-value-counter --fieldName=entities.hashtags.text --name=hashtags"
stream deploy --name tweetlang --properties "app.field-value-counter.spring.cloud.deployer.cloudfoundry.services=df-redis"
stream deploy --name tagcount --properties "app.field-value-counter.spring.cloud.deployer.cloudfoundry.services=df-redis"
stream deploy --name tweets
First stream named tweeets uses log sink just to output input as it is. The rest streams use field-value-counter sink for lang and entities.hashtags.text fields.
Field Value Counter counts occurrences of unique values for a named field in a payload. For example,
payload = [{"name": "aaa", "text":"hello"}, {"name": "bbb", "text":"hi"}, {"name": "aaa", "text":"hi"}, {"name": "ccc", "text":"hello"}]
field-value-counter("name") = {"aaa":2, "bbb":1, "ccc":1}
field-value-counter("text") = {"hello":2, "hi":2}
Three streams will be deployed.

You can see raw tweet log from log sink.

And now you can see the bubble or pie chart on how many hashtags/language are tweeted.

The charts will be updated automatically 😁:
Next Steps
- Enjoy other source/processor/task
- Create your own module
- Try experimental task functionallity
- Integrate config server using Spring Cloud Services in PCF Dev
- Try other platforms such as YARN, Kubernetes and Mesos